OpenAI刚刚推出了新的GPT-4O音频模型,以改善识别和人声合成。现在,它们比他们的前任更精确,现在可以控制AI的语气和语调,从而为更自然和个性化的人声互动打开了道路。

音频型号用于更好的语音互动
因此,OpenAI推出了三种新的音频型号:GPT-4O-Transcribe,GPT-4-MINI-TRANSCIBE和GPT-4O-MINI-TTS。他们的目标?使声乐剂在理解和口头表达方面更加自然,更精确。这些模型可通过想要增加容量的开发人员可以访问到他们的申请。
GPT-4O-Transcribe和GPT-4-Mini-Transcribe型号旨在将单词转换为文本,以更高的精度为OpenAI的旧窃窃私语模型。了解不同的口音,过滤背景噪声并管理语音速度变化,他们的效率将特别值得注意。在评估100多种语言的转录的基准速度上,这些模型比以前的版本显示出更好的结果,甚至超过了某些竞争解决方案。
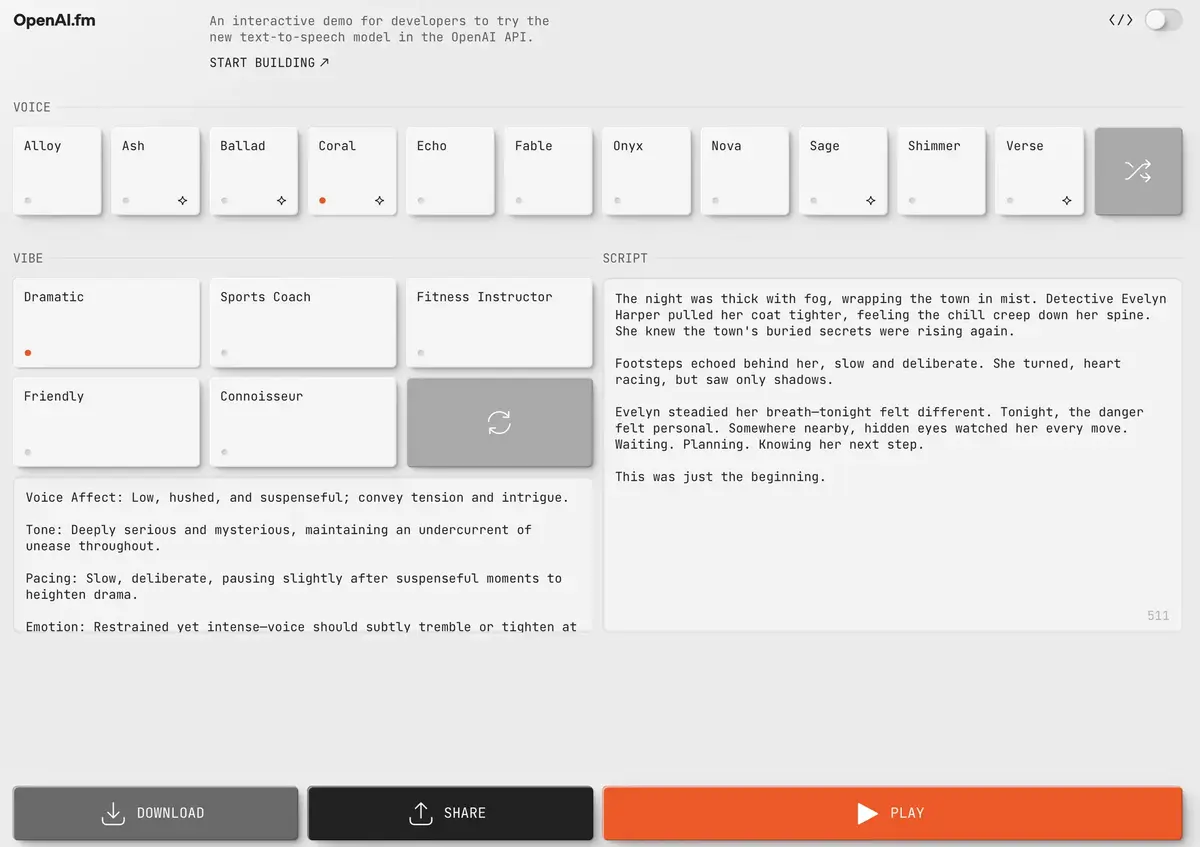
推动语音自定义
真正的新颖性来自GPT-4O-Mini-TTS模型。这使开发人员不仅可以修改AI所说的话,还可以修改它的说法。多亏了一种称为的技术可管道性
,他们可以要求模型以欢乐,镇定甚至怪异的语气说话,具体取决于所需的用途。此选项对于客户服务或音频叙述特别有用。 OpenAI还启动了一个名为OpenAI.FM的演示平台,该平台允许用户测试这些新声音并探索其不同的个性化选项。您可以飞跃,每个人都可以访问它。
可访问的价格
这些新型号以相当实惠的价格可通过OpenAI API获得。GPT-4O-transcibe的价格约为0.600分,而GPT-4O-MINI-TRASCRIBL的价格约为每分钟0.300。就其部分而言,GPT-4O-MINI-TTS的成本约为每分钟1.500。得益于SDK代理的更新,在现有代理中的实现也可以简化,这使开发人员仅在九行代码中添加了人声功能。
Openai计划进一步改善其人声模型,特别是通过开发创建个性化声音的选项,并确保最佳使用安全性。该公司还致力于将其音频模型集成到其他格式(例如视频)中,并具有提供越来越现实的IA相互作用的野心。





